
How We Used RAG to Build a Smarter Document Classification System
We applied Retrieval-Augmented Generation (RAG) to a real-world DLP project. Here's what we learned about chunking strategies, chunk-level tagging, and why the quality of your knowledge base matters more than the model you pick.


Retrieval-Augmented Generation (RAG) has quickly become one of the most important architectural patterns in AI development. Instead of relying solely on what a model learned during training, RAG combines real-time retrieval from an external knowledge base with the generative power of large language models, producing responses grounded in actual data, with far fewer hallucinations.
Most recently, we applied this approach to a DLP (Data Loss Prevention) project. We'll be sharing more details about it in a future post, but for now, let's talk about one of the most critical technical decisions we faced: chunking.
Why Chunking Makes or Breaks a RAG System
The documents we worked with were large and packed with everything from technical specs to business-sensitive content. A simple, document-level classification approach wasn't going to cut it. The real insight was that how you slice your documents before feeding them into the system determines the quality of everything that follows: the search, the retrieval, and ultimately the output.
Based on our previous experience with similar projects, we chose Weaviate as our vector database and knowledge base. Getting the segmentation right was an iterative process. Too large, and the system loses precision. Too small, and it loses context. We went through several approaches, starting from simple rule-based splitting and gradually moving toward more sophisticated methods where an additional AI model helped determine the most meaningful boundaries within a document. The right strategy ultimately depended on the complexity and structure of the content itself.
What this process taught us is that the way information is organized and indexed is just as important as the AI model interpreting it. Investing time in getting that foundation right has a direct and measurable impact on the accuracy of the system's output.
Tagging at the Chunk Level, Not the Document Level
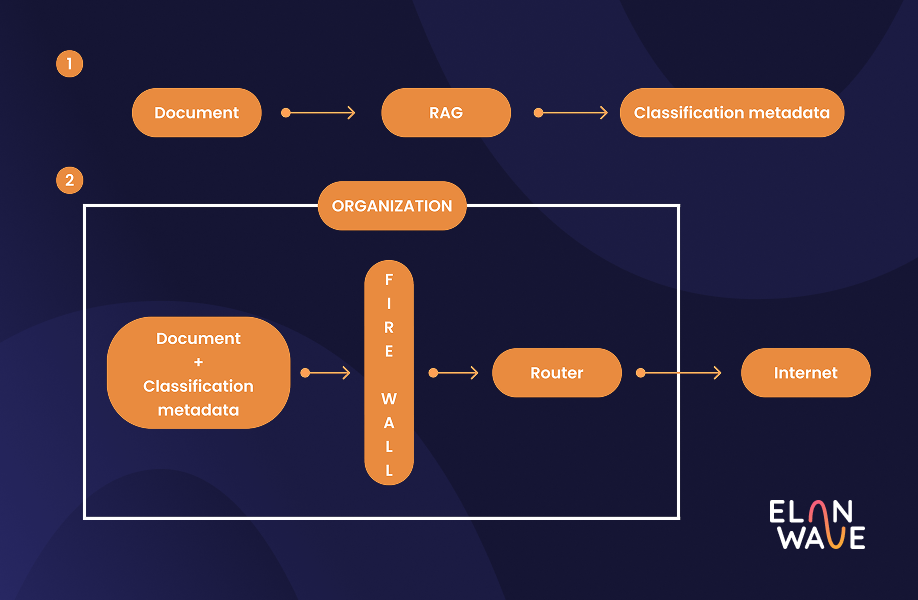
One of our most important design decisions was to tag individual chunks rather than entire documents. Each segment carried its own metadata, including an estimated sensitivity level and a textual explanation detailing the reasoning behind that specific classification. When processing a new document, it went through the same chunking pipeline and then RAG was applied to each chunk individually, retrieving the most semantically similar pre-labeled segments provided by domain experts before the LLM made its assessment.
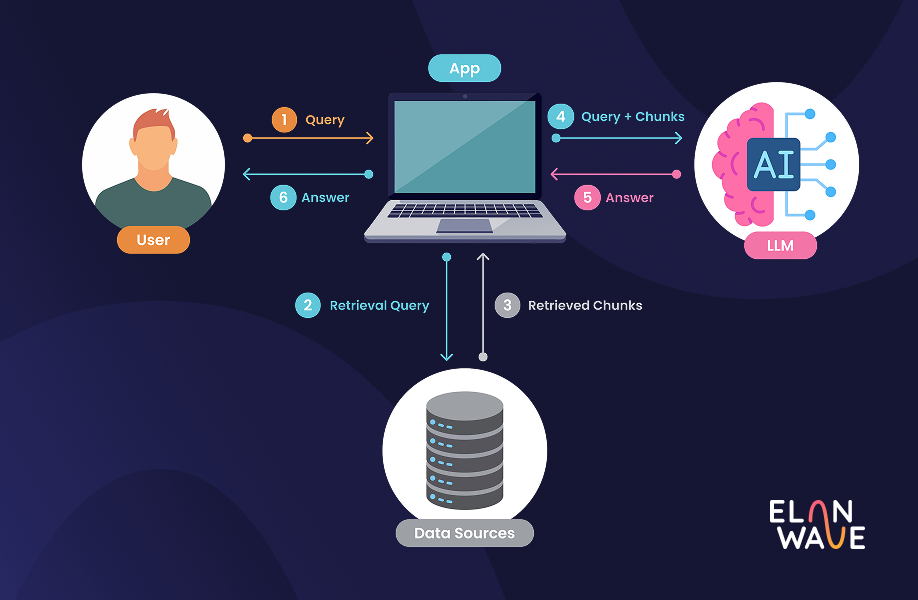
This meant the system could flag a single sensitive paragraph within an otherwise routine document, rather than marking the entire file as high-risk. That level of precision matters, both for accuracy and for the trust of the people relying on these outputs.
Our assumptions going in turned out to be correct: improving the quality and diversity of examples in the knowledge base had a bigger impact on performance than switching to a more powerful model. This is where domain expert annotation becomes truly valuable. It's not just about feeding the system more data, it's about feeding it the right data. Through carefully curated examples, we have the ability to encode what actually matters to our organization, making the system's decisions both more accurate and more aligned with our specific standards.
The Takeaway
Getting RAG to work well in production takes more than picking the right model or vector database. The chunking strategy, the quality of your indexed examples, and how tightly retrieval and generation are integrated. These are the things that actually determine whether the system holds up under real conditions. We had to learn some of that hard way. In a domain like data loss prevention, where the output needs to be both accurate and explainable, there's not much room for shortcuts.
More on the DLP project coming soon.
Interested in something similar for your business?
We offer a free evaluation to help you understand what the right solution looks like for your specific context.
Book free consultation
Let's talk!